The Problem: Finding a Needle in a Haystack
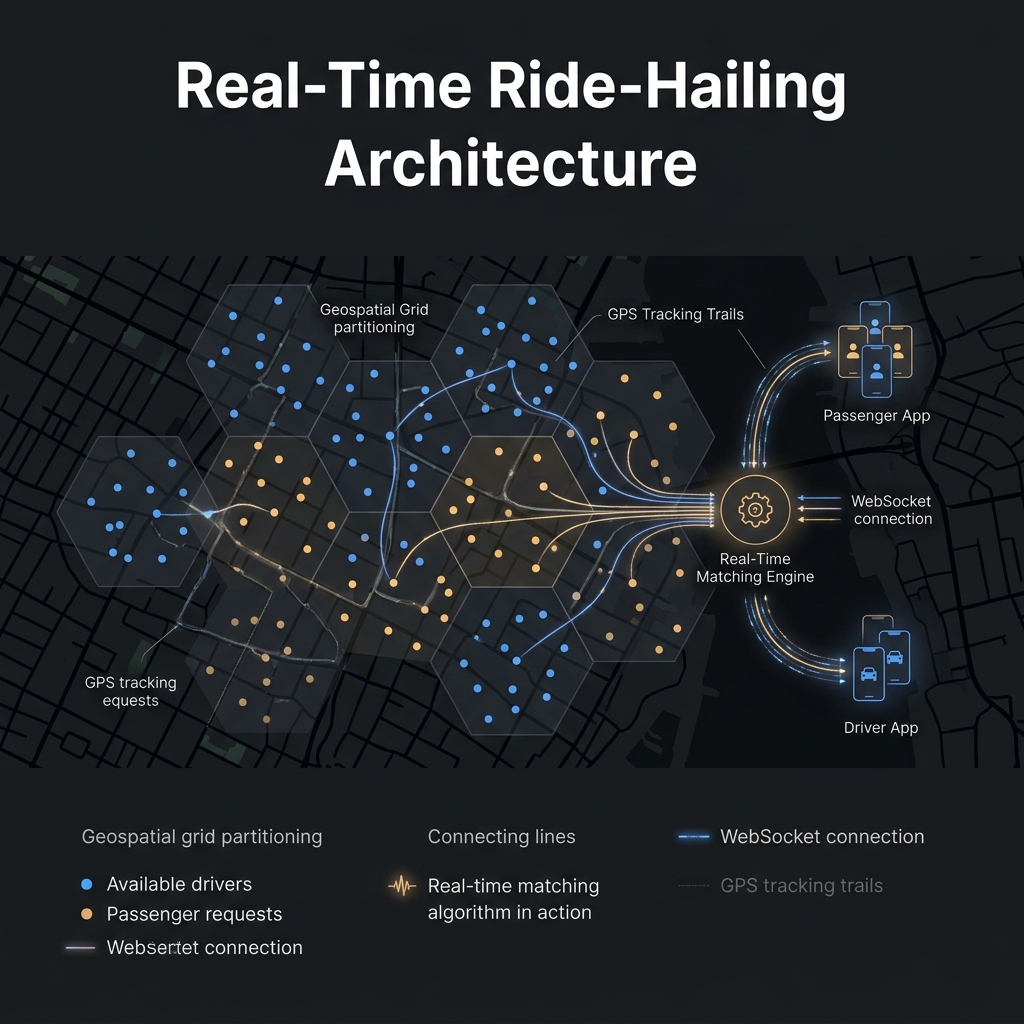
Answer-first: Uber and Grab find the nearest available driver in under 100ms by dividing the Earth’s surface into hexagonal cells (H3 index at Resolution 8, each ~0.74 km²). Instead of calculating distance to every driver, they look up only the 7 cells nearest to the rider — reducing millions of comparisons to dozens.
When you tap “Book” on Grab, the system must find the most suitable driver within a radius of a few kilometers. But the system is tracking millions of drivers simultaneously. The naive approach — calculating the distance from you to every driver — is impossible:
The Naive Approach (Brute Force):
SELECT * FROM drivers
WHERE ST_Distance(driver_location, rider_location) < 2000 -- 2km
ORDER BY ST_Distance(driver_location, rider_location)
With 5 million drivers → 5 million distance calculations
Latency: takes seconds → Unacceptable
The solution: Divide the map into a grid (Spatial Indexing) to narrow down the search space from millions to just a few dozen.
Method 1: Geohash
Geohash encodes coordinates (latitude, longitude) into a character string. The longer the string, the smaller and more precise the grid square:
Coordinates: 10.7769, 106.7009 (District 1, HCMC)
Geohash: w3gvk1 (cell ~1.2km × 0.6km)
w3gvk1e (cell ~153m × 153m)
w3gvk1e7 (cell ~38m × 19m)
Important characteristic: Prefix sharing
w3gvk1e ← Cells sharing a prefix are located near each other
w3gvk1f
w3gvk1g
Advantages
- Simple and easy to understand.
- Database-friendly: you can use a LIKE query (
WHERE geohash LIKE 'w3gvk1%'). - Redis supports it natively (
GEOADD,GEOSEARCH).
A Serious Disadvantage: The Edge Problem
Geohash divides the map into squares. Two points right next to each other, but situated on the edges of two completely different squares, will have entirely different prefixes — the system won’t find the driver even if they are only 50 meters away.
┌──────────┬──────────┐
│ │ │
│ w3gvk1 │ w3gvk3 │ ← Two cells with completely different prefixes
│ │ │
│ ●──────────○ │ ← Very close but in different cells
│ │ │
└──────────┴──────────┘
The Workaround: Always search the current cell + the 8 neighboring cells (a 3x3 grid). But this creates many false positives in the corners.
Method 2: H3 — Uber’s Hexagonal Grid
Uber developed H3 (Hexagonal Hierarchical Spatial Index) to resolve all the limitations of Geohash. It is an open-source spatial indexing system that partitions the entire surface of the Earth into hexagons.
Why are hexagons better than squares?
Squares (Geohash): Hexagons (H3):
┌────┬────┬────┐ ╱╲ ╱╲
│ │ │ │ ╱ ╲╱ ╲
│ d │ ? │ │ │ d ││ d │
│ │ │ │ ╲ ╱╲ ╱
├────┼────┼────┤ ╲╱ ╲╱
│ d │ ● │ │ ╱╲ ● ╱╲
│ │ │ │ │ d ││ d │
├────┼────┼────┤ ╲ ╱╲ ╱
│ │ │ │ ╲╱ ╲╱
└────┴────┴────┘ ╱╲ ╱╲
│ d ││ d │
d = distance to ● ╲ ╱╲ ╱
╲╱ ╲╱
Squares: 4 near neighbors (edges) Hexagons: 6 neighbors
4 far neighbors (corners) ALL at the SAME distance!
→ Uneven distances → Uniform distance
Equidistant: Every neighboring cell of a hexagon is an equal distance from its center. With squares, corner cells are √2 times (~1.41 times) further away than edge cells. This unevenness creates biases in search algorithms.
16 Levels of Resolution
H3 supports 16 levels of resolution, from level 0 (covering continents) to level 15 (a few square meters):
| Resolution | Average Area | Used For |
|---|---|---|
| 0 | ~4,357,449 km² | Continental level |
| 4 | ~1,770 km² | City/Province level |
| 7 | ~5.16 km² | Surge Pricing zones |
| 8 | ~0.74 km² | Finding drivers (most common) |
| 9 | ~0.105 km² | Precise matching |
| 12 | ~0.003 km² | Street-level |
Uber uses Resolutions 7-9 for the vast majority of its operations: finding drivers, calculating surge pricing, and analyzing supply and demand.
K-Ring — Neighborhood Search
A K-Ring is a collection of all cells within K steps from a center cell:
K=0 (center cell only): K=1 (center cell + 6 neighbors):
╱╲ ╱╲ ╱╲
╱ ╲ ╱ ╲╱ ╲
│ ● │ │ ││ │
╲ ╱ ╲ ╱╲ ╱
╲╱ ╲╱ ╲╱
╱╲ ● ╱╲
1 cell │ ││ │
╲ ╱╲ ╱
╲╱ ╲╱
7 cells
K=2: 19 cells K=3: 37 cells
Algorithm to find drivers:
- Convert the rider’s coordinates into an H3 index (resolution 8).
- Calculate K-Ring(1) → 7 hexagonal cells.
- Find all drivers currently in these 7 cells from Redis.
- If not enough drivers are found → expand to K-Ring(2) → 19 cells.
- Sort by actual ETA (not just straight-line distance).
Code Example (Go)
import "github.com/uber/h3-go/v4"
// Convert coordinates to H3 index
func findNearbyDrivers(riderLat, riderLng float64, radius int) []string {
// Resolution 8: each cell is ~0.74 km²
riderCell := h3.LatLngToCell(h3.LatLng{Lat: riderLat, Lng: riderLng}, 8)
// K-Ring: get all cells within a radius of K steps
searchCells := h3.GridDisk(riderCell, radius)
var driverIDs []string
for _, cell := range searchCells {
// Look up in Redis: key = H3 cell, value = list of driver IDs
cellKey := fmt.Sprintf("drivers:h3:%s", cell.String())
ids := redisClient.SMembers(ctx, cellKey).Val()
driverIDs = append(driverIDs, ids...)
}
return driverIDs
}
Method 3: Google S2 Geometry
S2 (developed by Google) is also utilized by Uber in their DISCO system (Matching Engine). S2 divides the Earth’s surface into square cells based on a projection onto a cube (following a Hilbert Curve).
Characteristics:
- Each cell is represented by a 64-bit integer → much faster for comparing, hashing, and sharding.
- 30 levels of resolution.
- Google Maps, Foursquare, and MongoDB Geospatial all use S2.
import "github.com/golang/geo/s2"
// S2: Find all cells covering a 2km radius from a point
func getCoveringCells(lat, lng float64, radiusM float64) []s2.CellID {
center := s2.PointFromLatLng(s2.LatLngFromDegrees(lat, lng))
cap := s2.CapFromCenterAngle(center, s2.Angle(radiusM/6371000.0))
coverer := &s2.RegionCoverer{
MinLevel: 14,
MaxLevel: 16,
MaxCells: 20,
}
return coverer.Covering(cap)
}
Storing Locations: Redis GEO
The locations of all online drivers are stored entirely in RAM (Redis) because query speeds are < 1ms. Traditional databases are not used because they are far too slow for 1.25 million writes/second.
Approach 1: Redis GEO (Built-in)
-- Add/update a driver's location
GEOADD drivers:active 106.7009 10.7769 "driver:abc123"
-- Find drivers within a 2km radius
GEOSEARCH drivers:active FROMLONLAT 106.7009 10.7769 BYRADIUS 2 km ASC COUNT 20
-- Result: ["driver:abc123", "driver:def456", ...]
Approach 2: Redis SET + H3 Index (Uber’s approach)
-- Each H3 cell is a Redis SET containing driver IDs
SADD drivers:h3:882a100d6dfffff "driver:abc123"
SADD drivers:h3:882a100d6dfffff "driver:def456"
-- When a driver moves to a new cell:
SREM drivers:h3:882a100d6dfffff "driver:abc123" -- Remove from old cell
SADD drivers:h3:882a100d71fffff "driver:abc123" -- Add to new cell
-- TTL to automatically clean up offline drivers:
-- Combine SET + EXPIRE or use a Sorted Set with timestamps
Comparing the Two Approaches
| Feature | Redis GEO | Redis SET + H3 |
|---|---|---|
| Radius Search | ✅ Built-in GEOSEARCH | ❌ Must calculate K-Rings manually |
| Sharding | ❌ Hard to shard (1 key holds everything) | ✅ Each H3 cell is a separate key → easy to shard |
| Scale Limit | ~a few million | ~tens of millions |
| Surge/Analytics Integration | ❌ | ✅ Count drivers/cell → calculate supply/demand instantly |
Uber uses the second approach (Redis + H3) because its sharding capabilities and integration with the Pricing Engine are far superior.
Consistent Hashing — Distributing GEO Data
When a massive city like Ho Chi Minh City has 200,000 online drivers, a single Redis node might not have enough RAM. The solution is Consistent Hashing to distribute the H3 cells across multiple Redis nodes:
H3 Cell "882a100d6dfffff" → hash() → Node A
H3 Cell "882a100d71fffff" → hash() → Node B
H3 Cell "882a100d73fffff" → hash() → Node A
Neighboring cells (a K-Ring) might reside on different nodes
→ A K-Ring query = a scatter-gather operation across multiple nodes
References & Further Reading
- Uber Engineering: H3 Hexagonal Hierarchical Spatial Index
- Google S2 Geometry Library
- Self-hosted routing: The same H3 hexagonal indexing used here for driver proximity is also the caching layer for GraphHopper Distance Matrix in production — replacing Google Maps API at $510/day.
Next, we will delve into the backbone of the entire system — Apache Kafka — where every GPS event, ride request, and acceptance flows. Continue reading Part 3 — Event Streaming: The Apache Kafka & Flink Backbone.