If you have ever built an internal chatbot for your company by chunking documents, creating embeddings, and stuffing them into Pinecone or Milvus… you have undoubtedly encountered this scenario:
User: “What was the Q3 revenue for product A, and how does it affect the Q4 strategy?” Bot: (Replies hesitantly, outputs last year’s Q2 figures, and completely loses context regarding the strategy).
Welcome to the disruption of Naive RAG (Retrieval-Augmented Generation).
Why Does Naive RAG Fail at the Enterprise Scale?
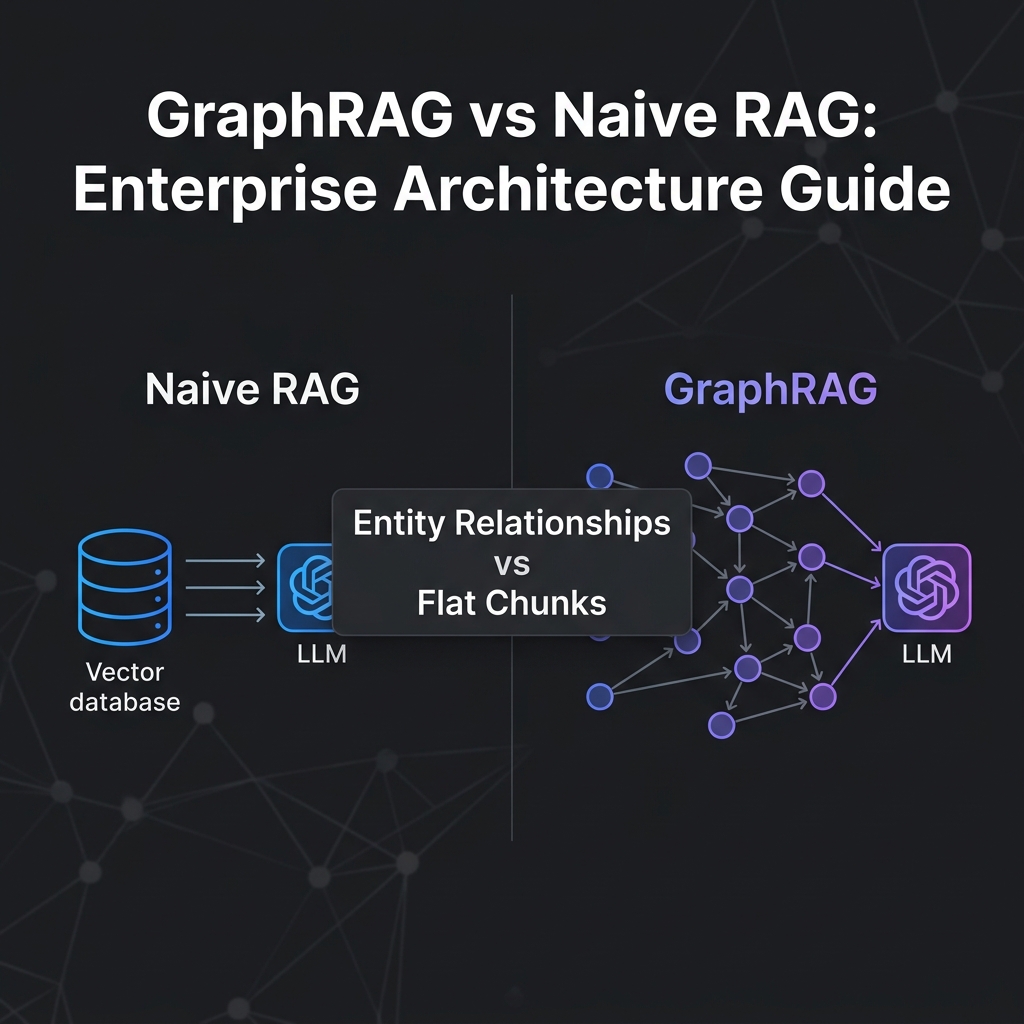
Naive RAG operates on keyword/semantic matching within a Vector space. It excels at answering isolated information retrieval queries. However, the Enterprise environment is rarely that simple.
- Relational Blindness: Vectors do not understand relationships. They do not know that “Product A” belongs to “Campaign X” managed by “Employee Y.” When a question demands multi-hop reasoning, Vector search is entirely blind.
- The Unstructured Nightmare: Corporate documents are not plain text. They are PDFs containing cross-page tables, business process diagrams, and messy emails. A basic chunker shreds table structures, turning financial data into meaningless gibberish.
- The RBAC Minefield: The CEO and an Intern must not receive the same answer from an LLM if the extracted data pertains to payroll. Basic Vector systems do not support Row-Level Security as well as traditional databases do.
- No Evals, No Trust: How do you know your bot is answering correctly 90% or 40% of the time? “Looks correct” is not an Engineering standard.
The Solution: Enterprise AI Data Pipeline & GraphRAG
To resolve this issue permanently, the AI Data Pipeline in 2026 has shifted to an entirely new architecture:
- Knowledge Graph combined with Vectors (GraphRAG): Data is not only stored as numbers but also as nodes and edges. The LLM can now “traverse” the graph to understand causal relationships.
- Advanced Ingestion: Utilizing small Vision models or advanced OCR techniques to accurately extract tables and diagrams before embedding.
- Metric-Driven Evals: Using LLM-as-a-Judge (like Ragas or TruLens) to automatically score each answer based on metrics: Context Precision, Answer Relevance, and Faithfulness (No Hallucinations).
In this Series, we will dive deep into each architectural layer, from extracting the first line of a PDF to building a robust Knowledge Graph, and finally establishing an automated evaluation system for the RAG Pipeline.
Next, let’s step into Part 1: The Convergence - Agentic RAG & GraphRAG.